Understanding Raft
Understanding Raft consensus algorithm
Raft is a consensus algorithm for managing a replicated log. In this article, I will explore what is distributed consensus and why do we need it? Specifically, I will discuss how the Raft algorithm works, and some implementation code in Go. The text and diagrams are liberally copied from the main Raft paper, but edited and re-organized as a future refrence for myself.
Consensus
Consensus algorithms allow a collection of machines to work as a coherent group that can survive the failures of some of its members.
Why do we need consensus?
Consensus algorithms typically arise in the context of replicated state machines. In this approach, state machines on a collection of servers compute identical copies of the same state and can continue operating even if some of the servers are down. Replicated state machines are used to solve a variety of fault tolerance problems in distributed systems. For example, large-scale systems that have a single cluster leader, such as GFS and HDFS typically use a separate replicated state machine to manage leader election and store configuration information that must survive leader crashes. Examples of replicated state machines include Chubby and ZooKeeper.
Raft consesnus
Raft separates the key elements of consensus, such as leader election, log replication, and safety. As described earlier, Raft is an algorithm for managing a replicated log. The log is just the state of the system.
Raft implements consensus by first electing a distinguished leader, then giving the leader complete responsibility for managing the replicated log. The leader accepts log entries from clients, replicates them on other servers, and tells servers when it is safe to apply log entries to their state machines.
Having a leader simplifies the management of the replicated log. For example, the leader can decide where to place new entries in the log without consulting other servers, and data flows in a simple fashion from the leader to other servers. A leader can fail or become disconnected from the other servers, in which case a new leader is elected.
Basics
The state of each server of the cluster is represented as:

At any given time each server is in one of three states: leader, follower, or candidate. In normal operation there is exactly one leader and all of the other servers are followers.
Leaders, Candidates and Followers
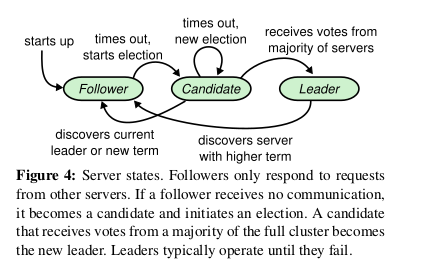
- Followers are passive: they issue no requests on their own but simply respond to requests from leaders and candidates
- The leader handles all client requests (if a client contacts a follower, the follower redirects it to the leader).
Time
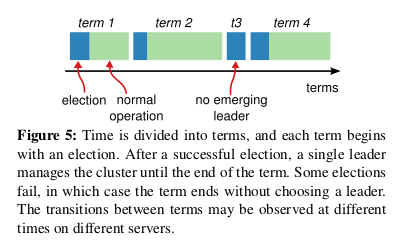
- Raft divides time into terms of arbitrary length, as shown in Figure 5
- Terms are numbered with consecutive integers, Each term begins with an election. Raft ensures that there is at most one leader in a given term.
- Different servers may observe the transitions between terms at different times, and in some situations a server may not observe an election or even entire terms.
- Terms act as a logical clock in Raft, and they allow servers to detect obsolete information such as stale leaders. Each server stores a current term number, which increases monotonically over time.
- Current terms are exchanged whenever servers communicate; if one server’s current term is smaller than the other’s, then it updates its current term to the larger value. If a candidate or leader discovers that its term is out of date, it immediately reverts to follower state. If a server receives a request with a stale term number, it rejects the request.
Communication between servers
Raft servers communicate using remote procedure calls (RPCs)
The basic consensus algorithm requires only two types of RPCs. RequestVote RPCs are initiated by candidates during elections, and AppendEntries RPCs are initiated by leaders to replicate log entries and to provide a form of heartbeat.
Leader Election
- A new leader must be chosen when the cluster starts operation or an existing leader fails.
- Raft uses a heartbeat mechanism to trigger leader election.
- A server remains in follower state as long as it receives valid RPCs from a leader or candidate. Leaders send periodic heartbeats (AppendEntries RPCs that carry no log entries) to all followers in order to maintain their authority.
- If a follower receives no communication over a period of time called the election timeout, then it assumes there is no viable leader and begins an election to choose a new leader.
- To begin an election, a follower increments its current term and transitions to candidate state. It then votes for itself and issues RequestVote RPCs in parallel to each of the other servers in the cluster.
- A candidate continues in this state until one of three things happens: (a) it wins the election, (b) another server establishes itself as leader, or (c) a period of time goes by with no winner.
- A candidate wins an election if it receives votes from a majority of the servers in the full cluster for the same term
- Each server will vote for at most one candidate in a given term, on a first-come-first-served basis
- The majority rule ensures that at most one candidate can win the election for a particular term
- Once a candidate wins an election, it becomes leader. It then sends heartbeat messages to all of the other servers to establish its authority and prevent new elections
- While waiting for votes, a candidate may receive an AppendEntries RPC from another server claiming to be leader. If the leader’s term (included in its RPC) is at least as large as the candidate’s current term, then the candidate recognizes the leader as legitimate and returns to follower state. If the term in the RPC is smaller than the candidate’s current term, then the candidate rejects the RPC and continues in candidate state.
- The third possible outcome is that a candidate neither wins nor loses the election: if many followers become candidates at the same time, votes could be split so that no candidate obtains a majority. When this happens, each candidate will time out and start a new election by incrementing its term and initiating another round of RequestVote RPCs. However, without extra measures split votes could repeat indefinitely.
- Raft uses randomized election timeouts to ensure that split votes are rare and that they are resolved quickly. To prevent split votes in the first place, election timeouts are chosen randomly from a fixed interval (e.g., 150–300ms)
- This spreads out the servers so that in most cases only a single server will time out; it wins the election and sends heartbeats before any other servers time out
- The same mechanism is used to handle split votes. Each candidate restarts its randomized election timeout at the start of an election, and it waits for that timeout to elapse before starting the next election; this reduces the likelihood of another split vote in the new election
The relevant code a candidate runs for for leader election is:
func (rf *Raft) triggerElection() {
rf.mu.Lock()
DPrintf("Debug, Candidate, I : %d set lock for starting election \n", rf.me)
rf.currentState = Candidate
rf.currentTerm += 1
lastLogIndex := rf.logIndex - 1
lastLogTerm := rf.log[lastLogIndex].Term
rf.votedFor = rf.me
DPrintf("Debug, Candidate, I : %d starting new election with term: %d \n", rf.me, rf.currentTerm)
peerCount := len(rf.peers)
// send request vote rpc to all servers
requestArgs := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: lastLogIndex,
LastLogTerm: lastLogTerm,
}
rf.persist()
rf.mu.Unlock()
voteCount := 1
halfPeerCount := peerCount / 2
DPrintf("Debug, Leader, I: %d request vote from peers\n", rf.me)
// ask for votes concurrently
voteChannel := make(chan bool, peerCount-1)
retryChannel := make(chan int, peerCount-1)
for i := 0; i < peerCount; i++ {
if rf.me != i {
go rf.requestVotesFromPeer(i, &requestArgs, voteChannel, retryChannel)
}
}
electionDuration := newRandDuration(ElectionTimeout)
electionTimer := time.NewTimer(electionDuration)
for {
select {
case vote := <-voteChannel:
if vote == false {
return
}
voteCount += 1
// majority votes, elected Leader
if voteCount > halfPeerCount {
rf.mu.Lock()
if rf.currentState == Candidate {
DPrintf("Debug, Candidate, I: %d got majority \n", rf.me)
rf.currentState = Leader
rf.initIndexes()
go rf.replicateLogs()
}
rf.mu.Unlock()
return
}
case follower := <-retryChannel:
rf.mu.Lock()
if rf.currentState == Candidate && rf.status==Live {
go rf.requestVotesFromPeer(follower, &requestArgs, voteChannel, retryChannel)
rf.mu.Unlock()
} else {
rf.mu.Unlock()
return
}
case <-electionTimer.C: // election timeout
rf.mu.Lock()
if rf.currentState == Candidate && rf.status==Live {
go rf.triggerElection()
}
rf.mu.Unlock()
return
}
}
}
func (rf *Raft) requestVotesFromPeer(peerId int, requestArgs *RequestVoteArgs, voteChan chan<- bool, retryChannel chan<- int) {
var voteReply RequestVoteReply
ok := rf.peers[peerId].Call("Raft.RequestVote", requestArgs, &voteReply)
if ok == true {
if voteReply.VoteGranted == true {
voteChan <- true
} else {
rf.mu.Lock()
if rf.currentTerm < voteReply.Term {
rf.currentState = Follower
rf.currentTerm = voteReply.Term
rf.votedFor = -1
rf.currentLeader = -1
rf.resetTimer(HEARTBEAT)
rf.persist()
// stop election
// wrap in go func because send to channel
// will be blocking unless there is receiver
go func() {voteChan <- false} ()
}
rf.mu.Unlock()
}
} else {
// call failed
DPrintf("Error, Leader, I: %d, peer: %d call failed", rf.me, peerId)
retryChannel <- peerId
return
}
}
The code for peers voting in an election is:
// RequestVote RPC handler.
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.currentTerm==args.Term && rf.votedFor==args.CandidateId {
reply.VoteGranted, reply.Term = true, rf.currentTerm
return
}
if args.Term < rf.currentTerm ||
(rf.currentTerm==args.Term && rf.votedFor!=-1){
DPrintf("Error, I : %d CANT vote for: %d, MYTERM: %d , Their TERM: %d \n",
rf.me, args.CandidateId, rf.currentTerm, args.Term)
reply.VoteGranted = false
reply.Term = rf.currentTerm
return
}
if args.Term > rf.currentTerm {
rf.votedFor, rf.currentTerm = -1, args.Term
rf.persist()
if rf.currentState != Follower {
rf.resetTimer(HEARTBEAT)
rf.currentState = Follower
}
}
// still trying to elect leader
rf.currentLeader = -1
reply.Term = args.Term
lastLogIndex := rf.logIndex - 1
if lastLogIndex == 0 && (rf.lastApplied!=0 || rf.commitIndex!=0) {
// never applied on this peer
}
if (rf.log[lastLogIndex].Term > args.LastLogTerm) ||
(rf.log[lastLogIndex].Term == args.LastLogTerm && lastLogIndex > args.LastLogIndex) {
// this server has longer log, under same term
reply.VoteGranted = false
return
}
reply.VoteGranted = true
rf.votedFor = args.CandidateId
rf.resetTimer(HEARTBEAT)
rf.persist()
DPrintf("I: %d, voted true for: %d\n", rf.me, args.CandidateId)
}Log Replication
Once the leader is elected, the cluster is ready to start serving client requests.
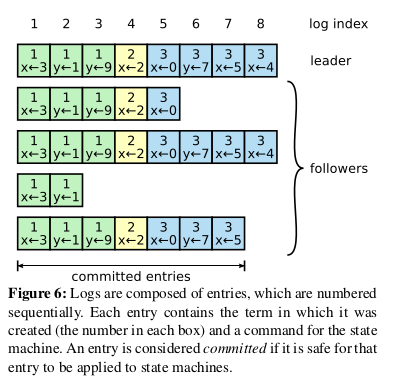
- Each client request contains a command to be executed by the replicated state machines.
- The leader appends the command to its log as a new entry, then issues AppendEntries RPCs in parallel to each of the other servers to replicate the entry. When the entry has been safely replicated (as described below), the leader applies the entry to its state machine and returns the result of that execution to the client
- If followers crash or run slowly, or if network packets are lost, the leader retries AppendEntries-RPCs indefinitely (even after it has responded to the client) until all followers eventually store all log entries
- Logs are organized as shown in Figure 6. Each log entry stores a state machine command along with the term number when the entry was received by the leader. Each log entry also has an integer index identifying its position in the log
- The leader decides when it is safe to apply a log entry to the state machines; such an entry is called committed
- Raft guarantees that committed entries are durable and will eventually be executed by all of the available state machines. A log entry is committed once the leader that created the entry has replicated it on a majority of the servers (e.g., entry 7 in Figure 6).
- The leader keeps track of the highest index it knows to be committed, and it includes that index in future AppendEntries RPCs (including heartbeats) so that the other servers eventually find out. Once a follower learns that a log entry is committed, it applies the entry to its local state machine (in log order)
- Raft maintains the following properties, which together constitute the Log Matching Property
in:
- If two entries in different logs have the same index and term, then they store the same command
- If two entries in different logs have the same index and term, then the logs are identical in all preceding entries
- In Raft, the leader handles inconsistencies by forcing the followers’ logs to duplicate its own. This means that conflicting entries in follower logs will be overwritten with entries from the leader’s log
- To bring a follower’s log into consistency with its own, the leader must find the latest log entry where the two logs agree, delete any entries in the follower’s log after that point, and send the follower all of the leader’s entries after that point
- With this mechanism, a leader does not need to take any special actions to restore log consistency when it comes to power. It just begins normal operation, and the logs automatically converge in response to failures of the AppendEntries consistency check. A leader never overwrites or deletes entries in its own log
The main functions for a leader sending AppendEntries RPC is:
// replicate logs on followers
func (rf *Raft) replicateLogs() {
retryCh := make(chan int)
done := make(chan struct{})
go rf.retryAppendEntries(retryCh, done)
for {
rf.mu.Lock()
if rf.status!=Live || rf.currentState != Leader {
rf.mu.Unlock()
done <- struct{}{}
return
}
DPrintf("Debug, LEADER, I: %d, replicate prev log index: %d \n", rf.me, rf.logIndex-1)
for peerId := 0; peerId < len(rf.peers); peerId++ {
if peerId != rf.me {
go rf.sendAppendEntriesRPCToPeer(peerId, retryCh, false)
}
}
rf.mu.Unlock()
time.Sleep(AppendEntriesInterval)
}
}
func (rf *Raft) sendAppendEntriesRPCToPeer(peerId int, retryCh chan<- int, empty bool) {
rf.mu.Lock()
if rf.currentState != Leader {
rf.mu.Unlock()
return
}
prevLogIndex := rf.nextIndex[peerId] - 1
prevLogTerm := rf.log[prevLogIndex].Term
var appendArgs AppendEntriesArgs
appendArgs = AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevLogIndex,
PrevLogTerm: prevLogTerm,
Entries: nil,
LeaderCommit: rf.commitIndex,
Len: 0,
}
if rf.logIndex == rf.nextIndex[peerId] || empty {
appendArgs.Len = 0
} else {
logs := rf.log[prevLogIndex+1:]
appendArgs.Len = len(logs)
appendArgs.Entries = logs
}
rf.mu.Unlock()
var appendEntryReply AppendEntriesReply
ok := rf.peers[peerId].Call("Raft.AppendEntries", &appendArgs, &appendEntryReply)
if ok == true {
rf.mu.Lock()
if appendEntryReply.Success == true {
// awesome, this peer is up to date
// update peers nextIndex and matchIndex
prevLogIndex, logEntriesLen := appendArgs.PrevLogIndex, appendArgs.Len
if prevLogIndex+logEntriesLen >= rf.nextIndex[peerId] {
rf.nextIndex[peerId] = prevLogIndex + logEntriesLen + 1
rf.matchIndex[peerId] = prevLogIndex + logEntriesLen
if logEntriesLen > 0 {
DPrintf("Debug, Leader, I: %d leader updated peer: %d\n", rf.me, peerId)
}
}
// check matchIndex for peers
// and update commitIndex
if (prevLogIndex+logEntriesLen < rf.logIndex) &&
(rf.commitIndex < prevLogIndex+logEntriesLen) &&
(rf.log[prevLogIndex+logEntriesLen].Term == rf.currentTerm) {
peerCount := len(rf.peers)
halfPeerCount, count, syncfollower := peerCount/2, 1, make([]int, 0, 1)
for j := 0; j < peerCount; j++ {
if j != rf.me && rf.matchIndex[j] >= prevLogIndex+logEntriesLen {
count += 1
syncfollower = append(syncfollower, j)
}
}
if count > halfPeerCount {
// commit the log
rf.commitIndex = prevLogIndex + logEntriesLen
DPrintf("Debug, Leader, I: %d leader updated commit index: %d\n", rf.me, rf.commitIndex)
rf.persist()
go rf.notifyApply()
}
}
} else {
// server is obsolete
if appendEntryReply.Term > rf.currentTerm {
rf.currentTerm, rf.currentState = appendEntryReply.Term, Follower
rf.votedFor, rf.currentLeader = -1, -1
rf.resetTimer(HEARTBEAT)
rf.persist()
} else {
// oops, this peer is NOT up to date
rf.nextIndex[peerId] = Max(1, Min(appendEntryReply.ConflictIndex, rf.logIndex))
}
DPrintf("Error, Leader, I: %d this peer: %d is NOT up to date", rf.me, peerId)
}
rf.mu.Unlock()
} else {
// call failed
// must do something
retryCh <- peerId
}
}
func (rf *Raft) retryAppendEntries(retryCh chan int, done <-chan struct{}) {
for {
select {
case peerId := <-retryCh:
go rf.sendAppendEntriesRPCToPeer(peerId, retryCh, true)
case <-done:
return
}
}
}
Similarly, the code for peers receiving new log entries is:
// AppendEntries RPC handler.
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.currentTerm > args.Term {
// Reply false if term < currentTerm
reply.Success = false
reply.Term = rf.currentTerm
DPrintf("Error, Peer, I : %d DONOT write to log from master: %d, I HAVE BIG TERM MISMATCH: %d \n", rf.me, args.LeaderId, reply.Term)
return
}
reply.Term = args.Term
rf.currentLeader = args.LeaderId
rf.resetTimer(HEARTBEAT)
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.votedFor = -1
rf.persist()
}
rf.currentState = Follower
if (args.PrevLogIndex >= rf.logIndex) || (rf.log[args.PrevLogIndex].Term != args.PrevLogTerm) {
// Reply false if log doesn’t contain an entry at prevLogIndex
// whose term matches prevLogTerm (§5.3)
conflictIndex := Min(rf.logIndex-1, args.PrevLogIndex)
conflictTerm := rf.log[conflictIndex].Term
for ; conflictIndex > rf.commitIndex && rf.log[conflictIndex-1].Term == conflictTerm; conflictIndex-- {
}
DPrintf("Error, Peer, I : %d DONOT write to log from master: %d, TERM MISMATCH: %d \n", rf.me, args.LeaderId, reply.Term)
reply.Success, reply.ConflictIndex = false, Max(rf.commitIndex+1, conflictIndex)
return
}
reply.Success, reply.ConflictIndex = true, -1
i := 0
for ; i < args.Len; i++ {
if args.PrevLogIndex+1+i >= rf.logIndex {
break
}
if rf.log[args.PrevLogIndex+1+i].Term != args.Entries[i].Term {
rf.logIndex = args.PrevLogIndex + 1 + i
rf.log = append(rf.log[:rf.logIndex]) //delete conflicts
break
}
}
for ; i < args.Len; i++ {
rf.log = append(rf.log, args.Entries[i])
rf.logIndex += 1
}
DPrintf("Debug, Peer, I : %d write to log from master: %d, LOGS: %v \n", rf.me, args.LeaderId, rf.log)
DPrintf("Debug, Peer, I : %d commitIndex: %d, leaderCommit: %d, myLogLength: %d \n",
rf.me, rf.commitIndex, args.LeaderCommit, args.PrevLogIndex+args.Len)
DPrintf("Debug, Peer, I : %d new commitIndex: %d \n", rf.me, Max(rf.commitIndex, Min(args.LeaderCommit, args.PrevLogIndex+args.Len)))
rf.commitIndex = Max(rf.commitIndex, Min(args.LeaderCommit, args.PrevLogIndex+args.Len))
rf.persist()
rf.resetTimer(HEARTBEAT)
go rf.notifyApply()
return
}
Raft Implementation
Implementing Raft takes a lot of time, patience and debugging ( and of course, coffee!). It was definitely one of the most challenging programs I ever wrote. It was also the first time I did any concurrent programming.
Some tips:
- Test extensively.
- Whenever possible, test every function to be sure it is doing the right thing
- Descriptive log statements
- Writing Raft, I had to write debug statements that I could use effectively. If I want to know everything that my cluster is doing (i.e. every operation, message), I will print a lot of lines!
- I want to be able to filter the debug statements effectively lines. Hence my debug statements constitute the following format:
[Error|Debug], [Peer|Leader], [statement], [serverId]
- I could filter the messages by leaders and followers easily in this format.
References